Parameters per batch handled in pharmaceutical process data pipelines.
Data Engineer | Snowflake, Python, SQL
Fayssal Zeggar
Data engineer building governed Snowflake pipelines and analytics-ready data products.
I work in regulated pharmaceutical manufacturing data environments, where reliability, traceability, and practical access for technical users matter as much as the pipeline code.
Toronto, Canada
Permanent Resident
No sponsorship required
French / English / Spanish
Power BI tables and data sources migrated and restructured into Snowflake.
SME users supported through simpler access to Snowflake data from JMP.
Reliable data engineering in regulated pharmaceutical manufacturing.
I design and maintain Snowflake-based ETL/ELT pipelines, integrate data from APRM, MES, SAP, and LIMS, optimize SQL models, and support analytics, AI, and ML initiatives with governed data access.
- Target roles: Data Engineer, Snowflake Data Engineer, Analytics Engineer.
- Professional core: Snowflake, Python, SQL, ETL/ELT, governance, analytics enablement.
- Portfolio project stack: Kafka, Airflow, dbt, Spark, FastAPI, Streamlit, Docker.
Professional profile
linkedin.com/in/fzeggar
FEATURED PROJECT
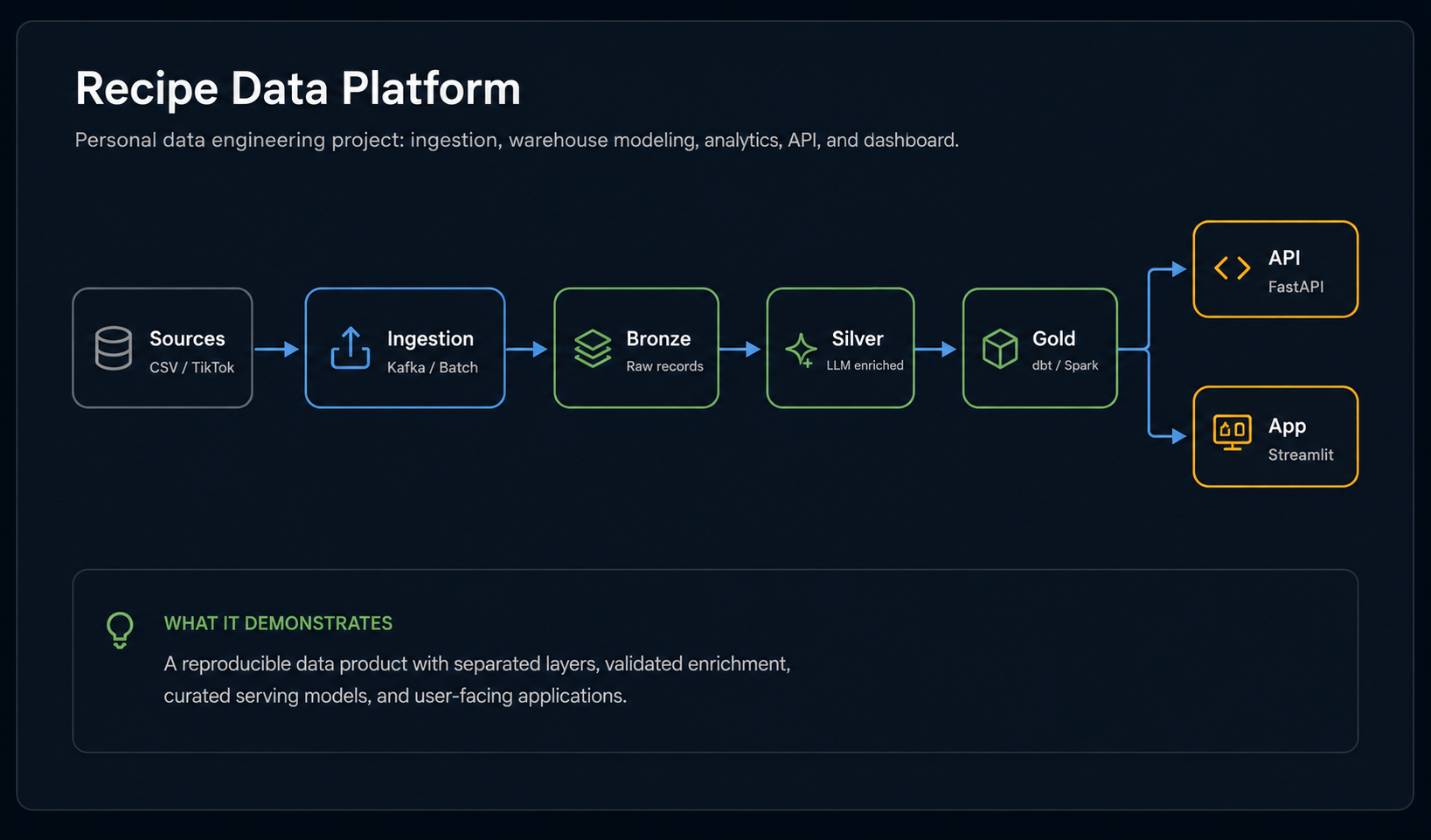
Recipe Data Platform
A personal project that demonstrates a full data platform from ingestion to warehouse modeling, orchestration, API serving, and dashboard exploration.
Recipe Data Platform
A personal data engineering project using Snowflake, Kafka, Airflow, dbt, Spark, FastAPI, Streamlit, and Docker to turn recipe content into structured, explorable data.
PROFESSIONAL CASE STUDY
Legacy manufacturing data integration, sanitized for public reading.
A short example of the kind of practical data engineering work I handle professionally: unclear source systems, secure access constraints, Snowflake ingestion, and reliable delivery.
Context
A legacy manufacturing historian had valuable process data, but access was not straightforward: older SQL behavior, limited documentation, and network restrictions between the source system and the cloud environment.
Action
I helped coordinate the secure network flow request, investigated the source structure, used a remote server to extract the needed records, and loaded the data into a Snowflake raw stage with a repeatable scheduled process.
Signal
The work shows the parts of data engineering that rarely fit in a tool list: legacy integration, cybersecurity coordination, schema discovery, operational reliability, and clear communication with technical stakeholders.
CAPABILITIES
Data engineering strengths backed by current professional work.
The focus is not a long tool list. It is the ability to move operational data into governed, reliable, analytics-ready systems.
Snowflake pipelines
Design and maintain ETL/ELT workflows for manufacturing and enterprise data, with attention to reliability, access control, and traceability.
SQL modeling and optimization
Restructure models, tune SQL, and make datasets easier for reporting, analysis, and downstream consumption.
Analytics enablement
Support Power BI, JMP, and SME workflows so users can work with trusted data without unnecessary manual extraction.
Integration and APIs
Connect enterprise and manufacturing systems, use REST APIs where appropriate, and keep ingestion paths explainable.
Cross-functional delivery
Translate needs from engineers, data scientists, process teams, and business stakeholders into reusable data flows.
DELIVERY APPROACH
From source complexity to trusted consumption.
My work is strongest where data has to be integrated carefully, governed properly, and made usable by real teams.
TECH STACK
Clear separation between professional strengths and portfolio project tools.
This keeps the site honest and easy to defend in a technical interview.
Daily data engineering, modeling, ingestion, and optimization.
Dashboards, SME access, process modeling, and data manipulation.
Code review, pipeline delivery, scheduling exposure, and YAML updates.
API-based integration and cloud prototyping from professional and R&D work.
Used in the Recipe Data Platform personal project.
ENGINEERING JUDGMENT
What I would improve next.
I like portfolios that show both what was built and what the builder would harden next. That is where engineering judgment becomes visible.
Productionize containers
Replace runtime dependency installation with custom Docker images for Airflow, API, Streamlit, and Spark.
Add stronger tests
Add dbt tests, parser unit tests, Kafka event normalization tests, and CI smoke checks for the local platform.
Improve demo reliability
Add a deterministic demo mode that does not depend on live TikTok access and monitor enrichment quality.